论文链接:https://arxiv.org/pdf/2404.19737
代码链接:
摘要
大语言模型(例如 GPT 和 Llama)在训练时会引入下一个 token 预测损失。在本研究中,我们提出训练语言模型一次性预测多个未来 token 可以提高样本效率。更具体地说,在训练语料的每个位置,我们要求模型使用 n 个独立的输出头(在共享模型主干上运行)预测接下来的 n 个 token。将多 token 预测视为辅助训练任务,我们测量了代码和自然语言模型在不增加训练时间的情况下提升的下游能力。该方法在模型规模较大时越来越有用,并且在多轮训练中也保持了其吸引力。在编码等生成基准测试中,我们的模型表现尤其显著,在这些基准测试中,我们的模型始终比强大的基线模型高出几个百分点。与同类的下一个 token 预测模型相比,我们的 13B 参数模型在 HumanEval 上解决了 12% 的问题,在 MBPP 上解决了 17% 的问题。在小型算法任务上的实验表明,多 token 预测有利于培养归纳头和算法推理能力。另外一个好处是,使用 4-token 预测训练的模型推理速度可提高 3 倍,即使 batch 较大也是如此。
1.介绍
人类将其最精妙的探索、惊人的发现和精美的作品浓缩成文字。基于所有这些语料训练的大语言模型 (LLM) 能够通过执行一项简单却强大的无监督学习任务:next-token prediction,提取出令人印象深刻的海量世界知识以及基本的推理能力。尽管最近取得了一系列令人瞩目的成就,但下一个 token 预测仍然是获取语言、世界知识和推理能力的低效方式。更准确地说,下一个 token 预测的 teacher forcing 机制会锁定局部模式,而忽略“艰难”的决策。因此,最先进的下一个 token 预测器需要的数据量比人类儿童高出几个数量级才能达到相同的流利程度。
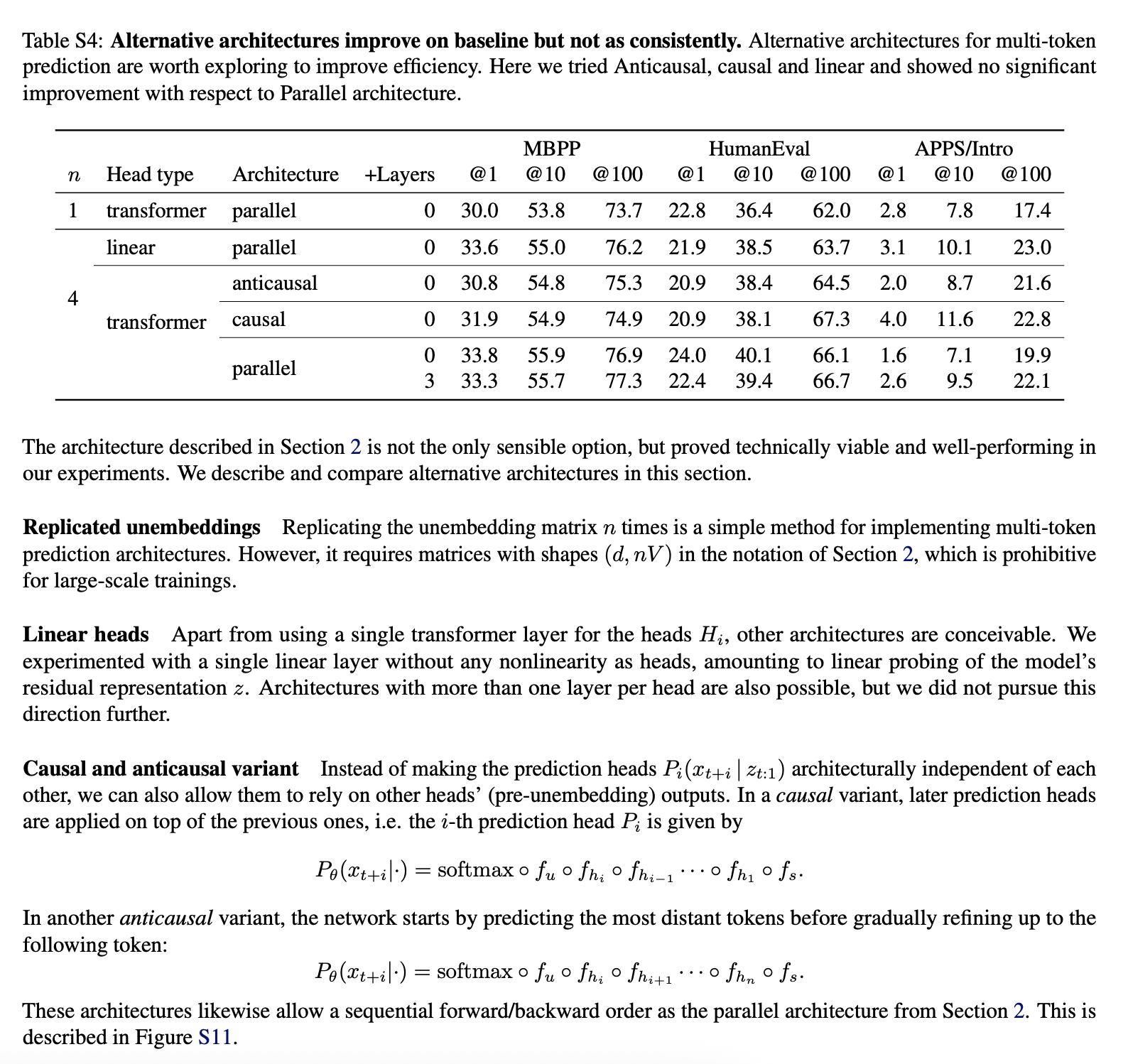
在本研究中,我们认为训练 LLM 一次性预测多个 token 将提高这些模型的样本效率。如图 1 所示,多 token 预测指示 LLM 一次性并行地从训练语料库中的每个位置预测 n 个未来 token。
Contributions。虽然先前的文献中已经研究过多 token 预测,但本研究提供了以下贡献:
- 我们提出了一种简单的多 token 预测架构,无需训练时间或内存开销(第 2 节)。
- 我们提供了实验证据,证明这种训练范式在规模上是有益的,多达 13B 个参数的模型平均可以解决大约 15% 的代码问题(第 3 节)。
- 多 token 预测支持自我推测解码,使模型在各种 batch size 的推理时间上速度提高 3 倍(第 3.2 节)。
多 token 预测虽然成本低廉且简单易用,但却是训练更强大、更快速的 Transformer 模型的有效改进方法。我们希望我们的工作能够激发人们对 LLM 新型辅助损失函数的兴趣,使其超越下一个 token 预测,从而提升这些卓越模型的性能、一致性和推理能力。
2.Method
标准语言模型通过执行下一个 token 预测任务来学习大型文本语料 。形式上,学习目标是最小化交叉熵损失:
其中 是我们正在训练的大语言模型,为了给定过去 token 的历史 ,最大化 作为下一个未来 token 的概率。
在本研究中,我们通过实现一个多 token 预测任务来推广上述方法。在训练语料的每个位置,模型被指示同时预测 个未来 token。这转化为交叉熵损失:
为了便于处理,我们假设我们的大语言模型 采用一个共享主干来生成观察到的上下文 的潜在表征 ,然后将其输入到 n 个独立的 head 中,并行预测 n 个未来 token 中的每一个(参见图 1)。这导致了多 token 预测交叉熵损失的分解如下:
在实践中,我们的架构由一个共享的 Transformer 主干 (它从观察到的上下文 产生隐藏表示 )、n 个独立的输出头(由 Transformer 层 实现)和一个共享的非嵌入矩阵 组成。因此,为了预测 n 个未来的 token,我们计算:
对于 ,其中 是我们的下一个 token 预测头。有关多 token 预测架构的其他变体,请参阅附录 B。
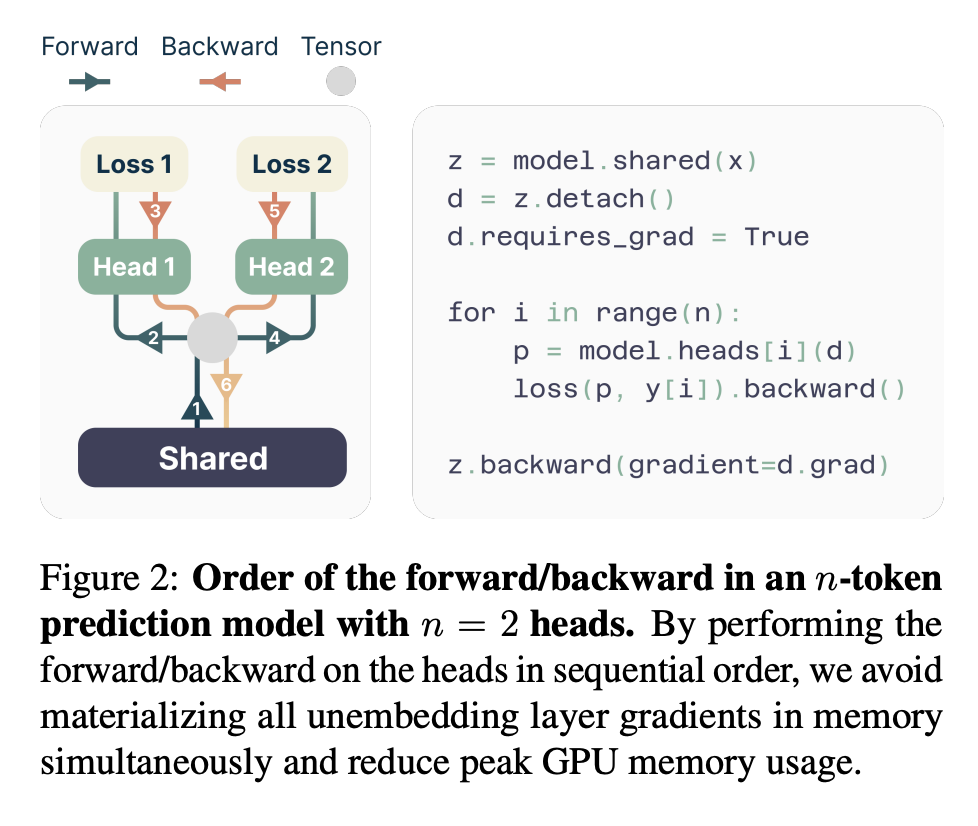
Memory-efficient implementation。训练多 token 预测器的一大挑战是降低其 GPU 内存占用率。要了解原因,请回想一下,在当前的 LLM 中,词表 远大于潜在表征的维度 d——因此,logit 向量成为 GPU 内存使用的瓶颈。将所有 logit 及其梯度(形状均为 )具体化的多 token 预测器的简单实现严重限制了允许的批次大小和平均 GPU 内存占用率。由于这些原因,在我们的架构中,我们建议仔细调整前向和后向操作的顺序,如图 2 所示。具体而言,在通过共享主干 进行前向传递之后,我们按顺序计算每个独立输出头 的前向和后向传递,从而在主干处累积梯度。虽然这会为输出头 创建 logit(及其梯度),但这些 logit 会在继续到下一个输出头 之前被释放,只需要长期存储 维主干梯度 。总之,我们将峰值 GPU 内存利用率从 降低到 ,且运行时没有任何开销(表 S5)。
Inference。在推理阶段,所提架构的最基本用法是使用下一个 token 预测头 进行原始的下一个 token 自回归预测,同时丢弃所有其他预测头。然而,可以利用额外的输出头,通过推测解码方法(例如分块并行解码——一种推测解码的变体,无需额外的草稿模型)以及使用类似 Medusa 树注意力机制的推测解码)来加速下一个标记预测头的解码。
3.Experiments on real data
我们通过七项大规模实验证明了多 token 预测损失的有效性。第 3.1 节展示了多 token 预测如何在增加模型规模时变得越来越有用。第 3.2 节展示了如何使用推测解码利用额外的预测头将推理速度提高 3 倍。第 3.3 节展示了多 token 预测如何促进学习长期模式,这一事实在字节级 tokenizer 的极端情况下最为明显。第 3.4 节表明,4 token 预测器在使用 32k 大小的 tokenizer 时可以获得强劲的收益。第 3.5 节说明,多 token 预测的优势在多次训练运行中依然有效。第 3.6 节展示了通过在 CodeContests 数据集上进行微调,使用多 token 预测损失进行预训练所带来的丰富表征。第 3.7 节表明,多 token 预测的好处可以带入自然语言模型,改进诸如摘要之类的生成性评估,同时在基于多项选择题和负对数似然的标准基准上不会出现显著的倒退。
为了公平地比较下一个 token 预测器和 n 个 token 预测器,后续实验始终比较具有相同参数量的模型。也就是说,当我们在未来的预测头中添加 n-1 层时,我们会从共享模型主干中移除 n-1 层。请参阅表 S14 查看模型架构,并参阅表 S13 查看我们在实验中使用的超参数概述。
3.1. Benefits scale with model size
为了研究这一现象,我们从零开始训练了六种规模的模型,参数数量从 300 M 到 13B 不等,使用了至少 91B 个代码 token。图 3 中 MBPP 和 HumanEval 的评估结果表明,在计算预算完全相同的情况下,使用多 token 预测,在给定固定数据集的情况下,大语言模型的性能可以大幅提升。
我们认为,这种仅在规模上才有用的特性可能是为什么多 token 预测迄今为止在很大程度上被忽视为大语言模型训练的一个有希望的训练损失的原因。
3.2. Faster inference
我们使用 xFormers 实现了具有异构 batch size 的贪婪自推测解码,并测量了我们最佳的 4 token 预测模型(具有 7B 个参数)的解码速度,该模型在完成从训练期间未见过的代码和自然语言测试数据集(表 S2)中获取的提示时的速度。我们观察到,代码的加速比为 3 倍,平均 3 条代码建议中有 2.5 条被接受,文本的加速比为 2.7 倍。在 8 字节预测模型上,推理加速比为 6.4 倍(表 S3)。使用多 token 预测进行预训练可以使额外的头比对下一个 token 预测模型进行简单的微调更加准确,从而使我们的模型能够充分发挥自推测解码的潜力。
3.3. Learning global patterns with multi-byte prediction
为了证明下一个 token 预测任务能够准确捕捉局部模式,我们采用了字节级 tokenizer 的极端情况,在 314B 字节(相当于约 116B token)上训练了一个 7B 参数的字节级 transformer。与下一个字节预测相比,8 字节预测模型取得了惊人的提升,在 MBPP pass@1 上解决了 67% 的问题,在 HumanEval pass@1 上解决了 20% 的问题。
因此,多字节预测是实现高效字节级模型训练的一种极具前景的方法。自推测解码可将 8 字节预测模型的速度提高 6 倍,从而完全补偿更长字节级序列在推理时的性能损失,甚至比下一个 token 预测模型快近两倍。8 字节预测模型是一个强大的基于字节的模型,尽管训练数据量减少了 1.7 倍,但其性能却接近基于 token 的模型。
3.4. Searching for the optimal n
为了更好地理解预测 token 数量的影响,我们对在 200B 个代码 token 上训练的 7B 规模模型进行了全面的消融。在此设置下,我们尝试了 n = 1、2、4、6 和 8。表 1 中的结果表明,在 HumanEval 和 MBPP 测试中,使用 4 个未来 token 进行训练的结果始终优于所有其他模型,分别在 1、10 和 100 个指标上:MBPP 分别为 +3.8%、+2.1% 和 +3.2%,HumanEval 分别为 +1.2%、+3.7% 和 +4.1%。有趣的是,对于 APPS/Intro,n = 6 领先,分别为 +0.7%、+3.0% 和 +5.3%。最佳窗口大小很可能取决于输入数据分布。对于字节级模型,最佳窗口大小在这些基准测试中更加一致(8 字节)。
3.5 Training for multiple epochs
在同一数据上进行多个 epoch 训练时,多 token 训练在下一个 token 预测方面仍然保持优势。虽然改进有所减弱,但在 MBPP 上,pass@1 的性能提升了 2.4%,在 HumanEval 上,pass@100 的性能提升了 3.2%,其余部分的性能表现相似。至于 APPS/Intro,在 200B token 的训练中,窗口大小 4 已经不是最佳选择。
3.6. Finetuning multi-token predictors
在微调方面,具有多 token 预测损失的预训练模型也优于下一个 token 模型。我们通过在 CodeContests 数据集上微调 3.3 节中的 7B 参数模型来评估这一点。我们将 4 token 预测模型与下一个 token 预测基线进行比较,并包含一个设置,其中 4 token 预测模型被剥离了额外的预测头,并使用经典的下一个 token 预测目标进行微调。根据图 4 中的结果,在 pass@k 上,两种对 4 token 预测模型进行微调的方法在 k 个步骤上的表现均优于下一个 token 预测模型。这意味着这些模型在理解和解决任务以及生成多样化答案方面都表现得更好。需要注意的是,CodeContests 是我们在本研究中评估的最具挑战性的编码基准。在 4 token 预测预训练的基础上,对下一个 token 预测进行微调似乎是总体上最佳的方法,这与经典的先使用辅助任务进行预训练,再针对特定任务进行微调的范式一致。详情请参阅附录 F。
3.7. Multi-token prediction on natural language
A. Additional results on self-speculative decoding
B. Alternative architectures